The Evolution Of Retrieval Systems In Retrieval Augmented Generation (Rag)
Jatin Shankar Srivastava
Explore how retrieval systems have evolved in RAG.
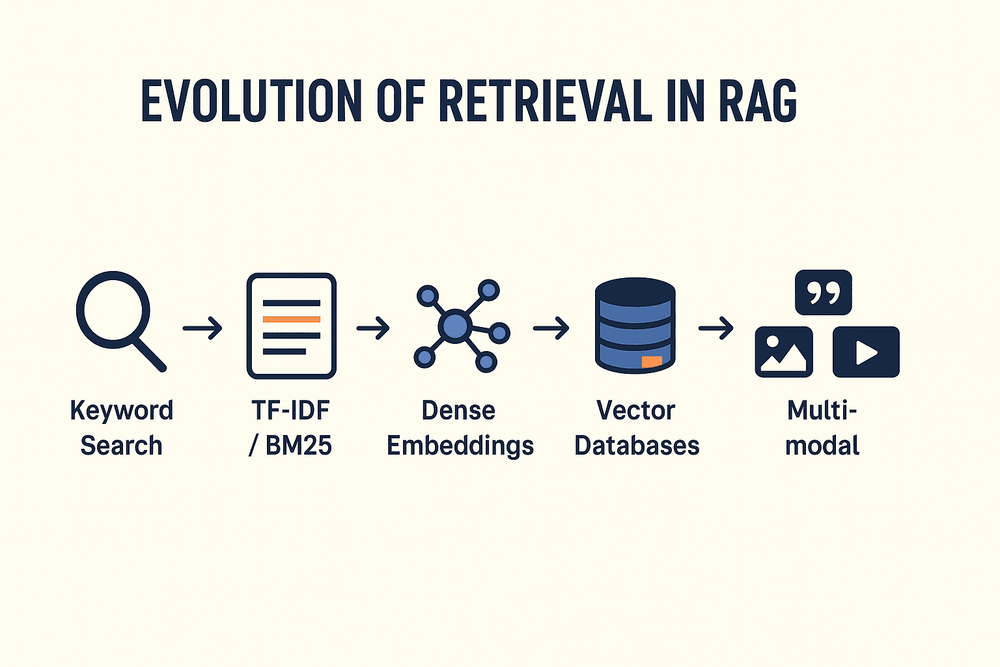
The Evolution of Retrieval Systems in Retrieval-Augmented Generation (RAG)
Retrieval-Augmented Generation (RAG) has emerged as one of the most promising paradigms in AI, combining the strengths of large language models (LLMs) with retrieval-based systems. The core idea is simple: instead of relying solely on the model’s internal memory, RAG augments generation with relevant information fetched from external knowledge bases. However, the efficiency and effectiveness of RAG depend heavily on how retrieval systems have evolved over the years.
1. Early Stages: Keyword-Based Retrieval
Before neural networks entered the picture, information retrieval was dominated by keyword search engines.
- BM25 & TF-IDF: Ranked documents based on keyword frequency and relevance scoring.
- Strengths:
- Fast and lightweight
- Good for structured keyword queries
- Weaknesses:
- Poor semantic understanding
- Could not capture synonyms, context, or intent
For RAG, keyword-based retrieval could surface documents, but the system lacked nuanced, semantically relevant information.
2. Dense Retrieval with Embeddings
With the rise of word embeddings (Word2Vec, GloVe) and contextual embeddings (BERT, RoBERTa), retrieval systems shifted from keywords to meaning.
- Dense Passage Retrieval (DPR): Used dual encoders to map queries and documents into the same embedding space.
- Strengths:
- Captured semantic meaning
- Worked better for natural language queries
- Weaknesses:
- Computationally heavier
- Required large vector databases
This marked a turning point where RAG systems could answer natural questions by retrieving semantically relevant passages.
3. Vector Databases and ANN Indexing
Scaling retrieval to millions or billions of documents brought a new challenge.
- Approximate Nearest Neighbor (ANN): Tools like FAISS, HNSW, and ScaNN enabled fast similarity search.
- Vector Databases: Pinecone, Weaviate, Milvus, Qdrant, and Vespa optimized large-scale embedding storage.
- Strengths:
- Real-time retrieval at scale
- Hybrid search (keyword + vector) became possible
- Weaknesses:
- Higher storage and infrastructure costs
With ANN indexing, RAG retrieval became both scalable and production-ready.
4. Multi-Vector and Cross-Encoder Retrieval
Single-vector representations were often not enough.
- ColBERT: Used late interaction between query and document tokens for fine-grained relevance.
- Cross-Encoders: Jointly encoded query + document pairs for higher accuracy.
- Hybrid Retrieval: Combined sparse (BM25) and dense methods for robust results.
This improved contextual precision and reduced irrelevant retrievals.
5. Memory-Augmented and Adaptive Retrieval
Modern retrieval systems are increasingly dynamic and adaptive.
- Adaptive Retrieval: Fetches variable numbers of documents depending on query complexity.
- Learned Indexes: Neural networks assist in prioritizing candidates.
- Context-Aware Retrieval: Uses conversation history or user profiles for better results.
- Long-Context Models: Even with 200k+ token models, retrieval adds reliability and reduces hallucinations.
6. The Rise of Multi-Modal Retrieval
Today’s RAG isn’t limited to text.
- Image, audio, and video retrieval using embeddings like CLIP (for images) and Whisper (for audio).
- Cross-Modal RAG: For example, retrieving both a product manual (text) and product image to support customers.
This expands RAG into wider real-world applications.
7. Retrieval Meets Agents
The latest trend is agent-driven retrieval.
- Self-Retrieval Agents: LLMs decide when and what to retrieve.
- Tool-Augmented Retrieval: Agents dynamically use APIs or search tools.
- Feedback Loops: Retrieved knowledge is validated and re-ranked by the model itself.
Retrieval is no longer static — it has become an interactive reasoning tool.
Conclusion: From Keywords to Intelligent Memory
Retrieval systems in RAG have grown from simple keyword search to highly optimized, multi-modal, context-aware architectures. Today, they:
- Understand semantics instead of just keywords
- Scale across billions of documents with vector databases
- Adapt dynamically to queries and contexts
- Integrate multi-modal knowledge sources
- Power intelligent AI agents
The future of retrieval in RAG lies in personalization, federated retrieval across private + public data, and deeper integration with reasoning frameworks.
Better retrieval means better grounding, fewer hallucinations, and more trustworthy AI.